Our Baselines
Before spending the time to build an extensive, predictive model for a dataset, it's important to first begin with baseline predictors. These baselines are used for comparison, to determine how effective our own model is, and, as a rule-of-thumb, our model must outperform these simple baselines to justify the amount of time and effort it takes to train and implement our developed model.
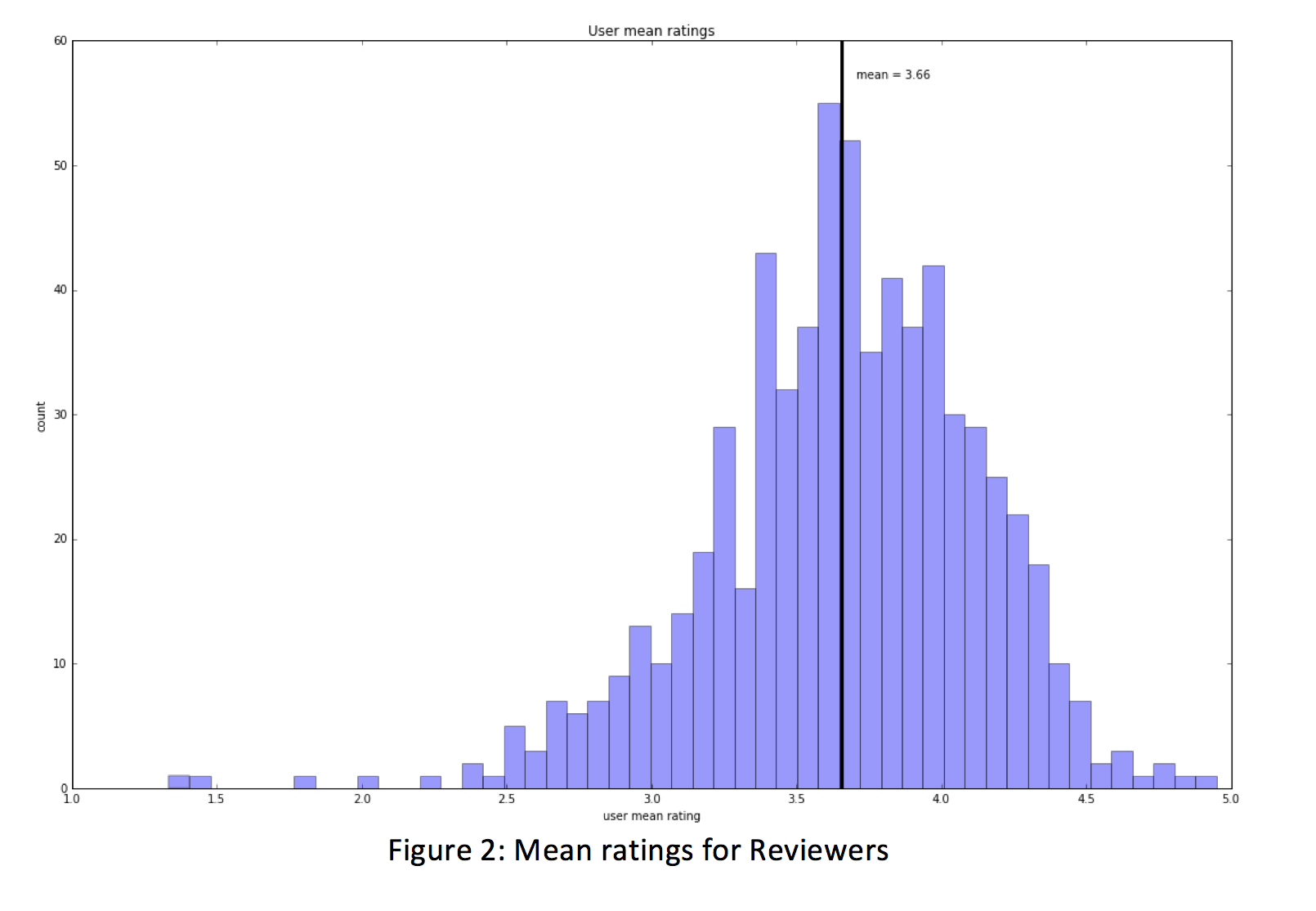
The first baselines we built were mean user rating and mean movie rating. The average movie rating of approximately 100k movie ratings was 3.29, with a standard deviation of .88.
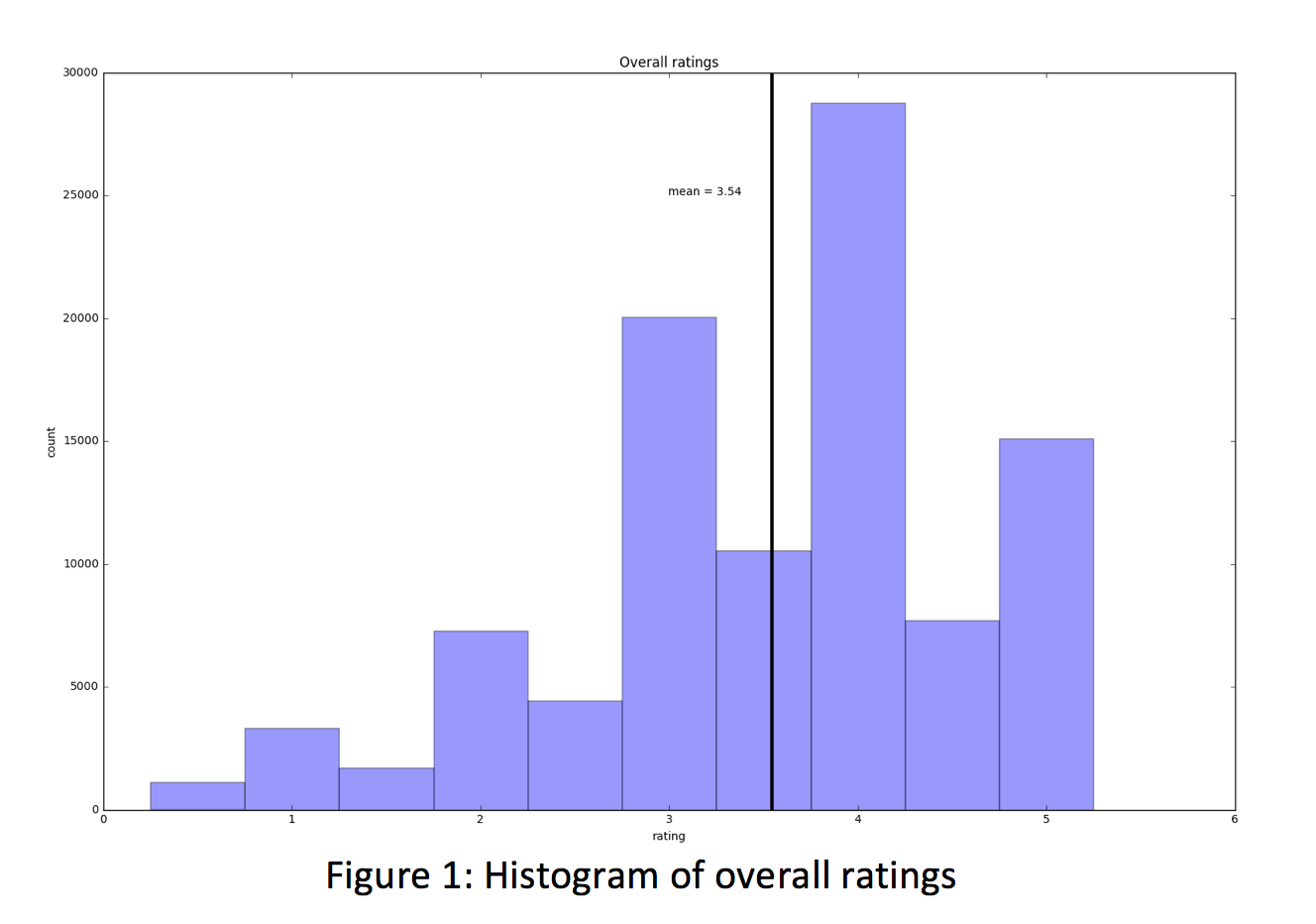
This mean is the value that R^2 (which is a measure of how well our x variable(s) explain the y variable) will use to calculate how well our model performs for the model. Not surprisingly, the model that uses the mean movie rating scored a 0 for the training set and very nearly a 0 for the test set. However, when we use the mean movie rating as a predictor for our model, we perform better than the total mean model with an of .12.
This is still a rather low performing model and can be explained by the fact that of the ~9k movies, approximately 3k of them only have a single rating and 1,200 have only 2 ratings. This means that 47% of the movies in our data have 2 or less ratings. For this reason, we are compelled to examine another method in which to build our model – beginning with using mean user rating as a predictor.
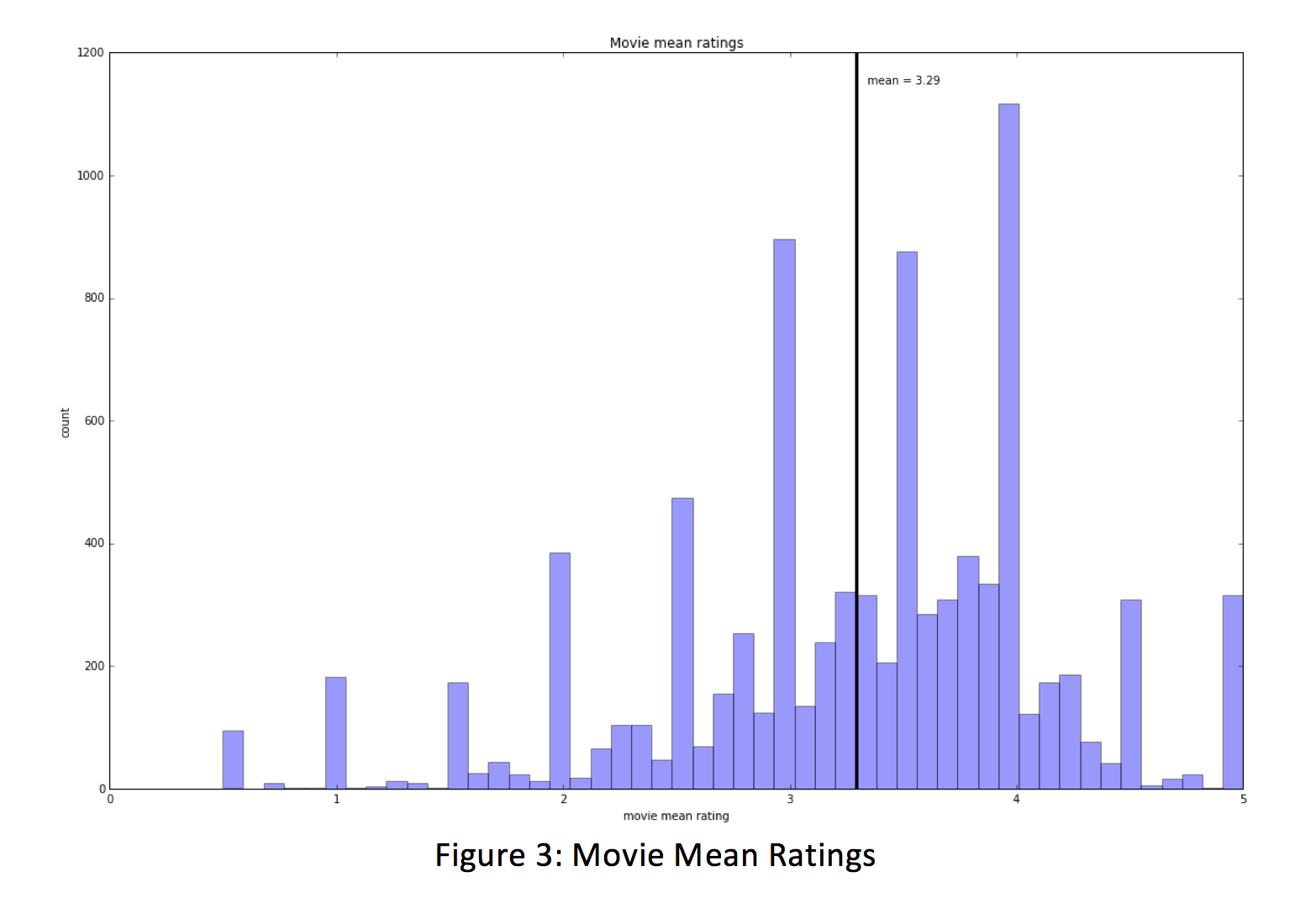
Of our 671 unique reviewers in the dataset, the mean user rating was 3.66, with a max user mean rating of 4.95 and a minimum user mean rating of 1.33. The distribution of mean user ratings appears to be normally distributed with a standard deviation of .47.
When we build a model using mean user ratings as a predictor, we see that our R^2 is .17, which is better performing than all of the other models so far.
For the third baseline, we decided to decouple the item and user variables and take into account both item (movie) and user effects, which is the same baseline predictor method. This method uses a regularization parameter, lambda, which we tuned to provide the highest R^2. Using this final baselining method, the score on the test set is .28, which is higher than the model that uses only the user mean review (=.17). This becomes the baseline for which any predictive model must outperform.