Data Cleanup
The first step in creating a workable dataset for this project was to combine the three datasets provided by MovieLens into a single, workable copy. After importing the data from three separate datasets and joining those data frames by movieID, we could start the data cleanup process.
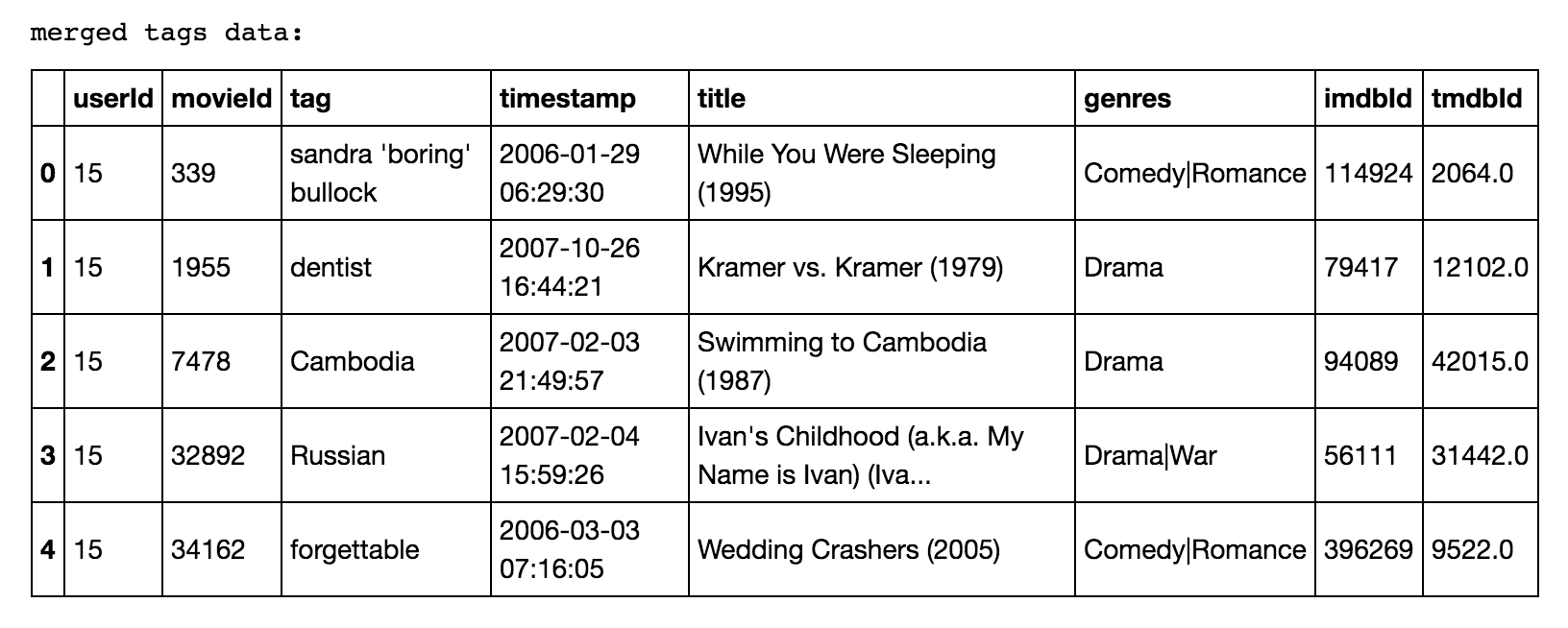
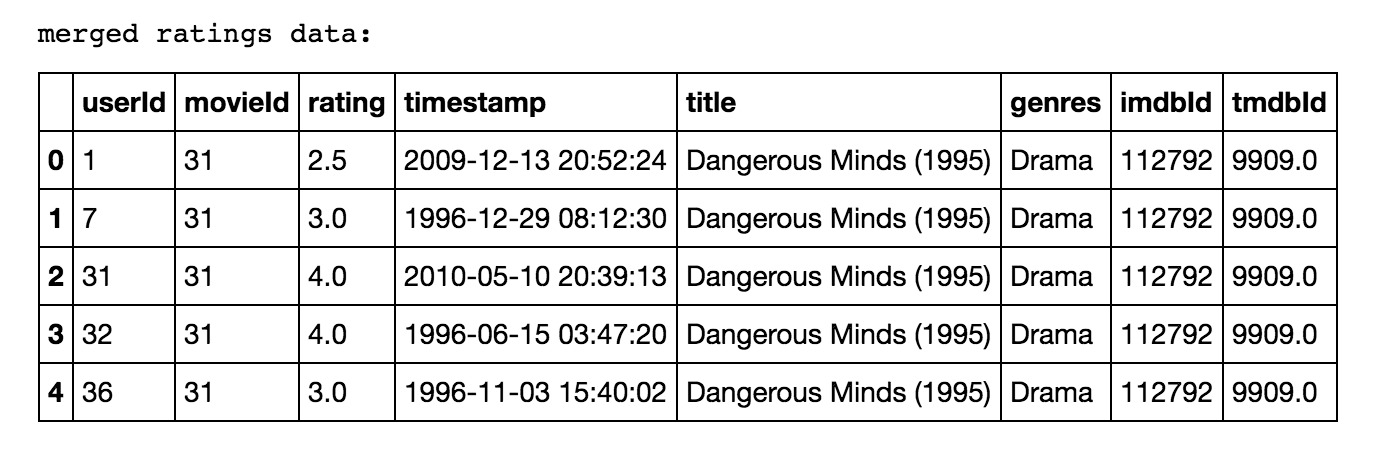
Cleaning the data from the source was simpler than we expected. Since our dataset didn’t dive into lengthy reviews for each movie (which would require lengthy sentiment analysis processing) but captured user ratings, genre, and a short tag to describe the reviewer’s take on the film, we were fairly fortunate to not need a lengthy cleansing process. Some films didn’t receive a genre tag and were subsequently tagged as ‘no genres listed.’ In this case, the data was temporarily converted into an empty string. As we progress throughout the project, we will breakout the tagged genres into a predictive feature for each film (which will include removing the ‘|’ from each string) and use those responses to build our model. For the purposes of initial analysis, the string was replaced with a blank value. Otherwise, the dataset was particularly well-structured and documented, readily available in an easily consumable CSV format.
In Python, we can import and merge our initial datasets like this:
Dataset = namedtuple('Dataset', ['ratings_df', 'movies_df', 'tags_df', 'links_df'])
def date_parse(time_in_secs):
return datetime.fromtimestamp(float(time_in_secs))
def read_data():
ratings_df = pd.read_csv('ml-latest-small/ratings.csv', parse_dates=['timestamp'], date_parser=date_parse)
movies_df = pd.read_csv('ml-latest-small/movies.csv')
tags_df = pd.read_csv('ml-latest-small/tags.csv', parse_dates=['timestamp'], date_parser=date_parse)
links_df = pd.read_csv('ml-latest-small/links.csv')
return Dataset(ratings_df, movies_df, tags_df, links_df)
def explore_data(dataset):
ratings_df = dataset.ratings_df
movies_df = dataset.movies_df
tags_df = dataset.tags_df
links_df = dataset.links_df
merged_movies_df = movies_df.merge(links_df)
merged_ratings_df = ratings_df.merge(merged_movies_df)
merged_tags_df = tags_df.merge(merged_movies_df)
print 'raw ratings data:'
display(ratings_df.head())
print
print 'raw movies data:'
display(movies_df.head())
print
print 'raw tags data:'
display(tags_df.head())
print
print 'raw links data:'
display(links_df.head())
print
print 'merged movies data:'
display(merged_movies_df.head())
print
print 'merged ratings data:'
display(merged_ratings_df.head())
print
print 'merged tags data:'
display(merged_tags_df.head())
print
dataset = read_data()
explore_data(dataset)
The code above is a way to merge our datasets and provide a quick visual snapshot of how we're transforming it for our use. Here is an example of our "Merged Ratings Data":
And this is what we find when we merge the tags data: